Excel 文件批量合并与数据清洗工具使用说明
需求
在工作中经常有很多从系统上下载导出的文件,很零散,而且平台没办法合并导出,有些导出了格式和文件类型都不一样,需要把这些用Python自动合并起来处理。如下图。
每个表大致的内容
合并后效果:
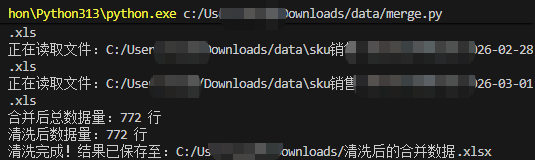
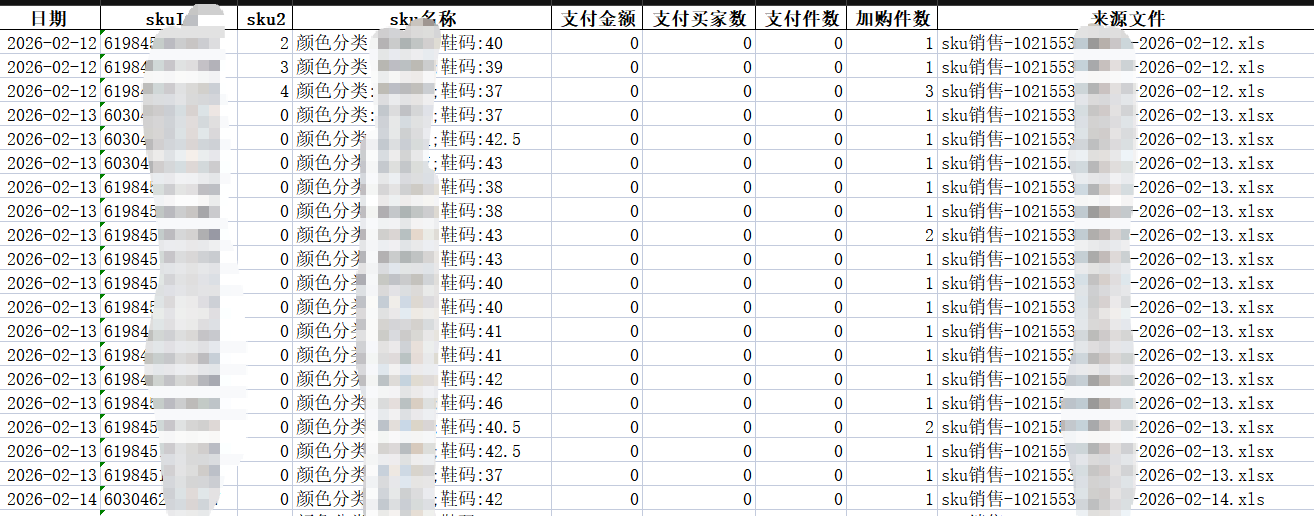
一、工具介绍
本工具基于 Python 的 pandas 库开发,可实现指定文件夹下所有 Excel 文件(.xls/.xlsx)的批量读取、合并,并完成一系列自动化的数据清洗操作,最终输出清洗后的合并 Excel 文件。适用于需要定期处理多份结构相似的 Excel 数据、统一数据格式和过滤无效信息的场景。
二、功能特性
多文件批量读取:自动遍历指定文件夹,筛选出有效 Excel 文件(跳过临时文件),支持.xls 和.xlsx 格式;
数据溯源:为每条数据添加 “来源文件” 列,便于追溯数据原始文件;
智能合并:自动对齐不同文件的列结构,缺失列填充 NaN;
数据清洗(可自定义)
- 填充缺失值为 0;
- 删除全空行和重复行;
- 处理日期格式(从文件名提取日期并标准化);
- 过滤无效数据(如加购件数为负数的记录);
- 调整列显示顺序(日期列置顶);
- 优化 skuId 格式(转成字符串,去除末尾.0,避免科学计数法);
结果保存:将清洗后的合并数据保存为新的 Excel 文件。
三、环境准备
1. 安装 Python和IDE
确保本地已安装 Python 环境(我使用的是3.13.1),可从Python 官网下载安装。
IDE我选择的是VS code。

2. 安装依赖库
打开命令提示符(CMD)或终端,执行以下命令安装所需库:
1 | pip install pandas openpyxl xlrd |
- pandas:核心数据处理库(我使用的是2.2.3);
- openpyxl:支持.xlsx 文件的读写(我使用的是3.1.5);
- xlrd:支持.xls 文件的读取(我使用的是2.0.1)。
四、使用步骤
1. 代码修改
注:计算机名字隐藏为xxx
打开代码文件(建议命名为 merge.py),根据实际需求调整以下参数:
1 | if __name__ == "__main__": |
input_folder:存放待处理 Excel 文件的文件夹绝对路径;output_excel:清洗后合并文件的保存路径及文件名。
2. 放置待处理文件
将需要合并的 Excel 文件统一放入上述input_folder指定的文件夹中,确保文件为.xls 或.xlsx 格式。
3. 运行代码
方式 1:命令行运行
打开命令提示符(CMD),切换到代码所在目录,执行:
1 | python merge.py |
方式 2:IDE 运行
在 PyCharm、VS Code 等 Python IDE 中直接运行 merge.py 文件。
4. 查看结果
运行完成后,控制台会输出各步骤日志(如读取的文件、合并 / 清洗后的数据行数),最终在output_excel指定路径下生成清洗后的合并 Excel 文件。
五、核心代码解析
1. 主函数定义
1 | import pandas as pd |
导入依赖库并定义主函数,接收文件夹路径和输出文件路径两个参数。
2. 遍历读取 Excel 文件
1 | for filename in os.listdir(folder_path): |
遍历文件夹,筛选有效 Excel 文件,读取文件并添加溯源列,异常文件跳过并打印错误信息。
我的文件导出后前五行需要排除
3. 数据合并与基础清洗
1 | if not all_data: |
合并所有读取的数据(concat),填充缺失值。
4. 高级数据清洗
1 | # 优化skuId格式 |
优化 skuId 显示格式,避免出现科学计数法,完成空行 / 重复行删除、日期提取与格式化、无效数据过滤、列顺序调整等核心清洗操作(可以根据实际情况进行自定义)。
5. 结果保存
1 | combined_df.to_excel(output_file, index=False) |
将清洗后的数据保存为 Excel 文件,不保留索引列。
六、注意事项
- 文件路径:Windows 系统路径建议使用双反斜杠(\\),或正斜杠(/),避免路径错误;
- 跳过行数:代码中
skiprows=5表示读取 Excel 时跳过前 5 行,需根据实际 Excel 表头结构调整; - 日期提取:日期提取逻辑假设文件名末尾包含 “YYYY-MM-DD” 格式的日期,若文件名格式不同,需修改
combined_df['日期'] = combined_df['文件名前缀'].str[-10:]这一行的切片规则; - 列名适配:代码中针对 “skuId”“加购件数”“日期” 等列的处理,需根据实际业务数据的列名调整;
- 异常处理:若部分 Excel 文件读取失败,控制台会打印错误信息,可根据提示检查文件是否损坏或格式异常。
七、常见问题解决
- **报错 “SyntaxWarning: invalid escape sequence ‘**:转义警告,可以在前面加上r,如replace(r’.0$’, ‘’, regex=True);
- 读取.xls 文件报错:xlrd 版本不适配,可根据提示调整
- 日期列全部显示 “未知”:文件名中无 “YYYY-MM-DD” 格式的日期,需检查文件名格式或修改日期提取逻辑;
- 数据合并后列缺失:不同 Excel 文件的列名不一致,pandas 会自动对齐,可检查源文件列名是否统一。
